Authors
LangChain on AWS Step Functions: Blogs Summaries into Notion
LLMs provide incredible capabilities at working with text in various ways and at a big scale.
As a cloud architect one of the things I found it works incredibly well is for is content summarization.
Something that I'm used to doing on a daily basis is following cloud provider blogs because I want to be well updated on what's new in the cloud space and what are the new offerings cloud providers announcing so that I stay up to date in conversations with various clients.
The thing is that there are so many blogs out there and the number of articles keeps accelerating so it’s quite hard to follow along for everything.
I also rely on various feeds in social media (LinkedIn, X), news (Google News) and at times a relevant article would come up.
I also rely on various heats of social media such as Linkedin, X and news feeds such as Google News for instance where some articles would come up on point but more often than not those feeds are getting polluted with irrelevant content and I’d get distracted quite often.
So I’ve figured what I could do is I to apply my engineering skillset to bring a little bit of automation powered by LLM capabilities to retrieve relevant information, extract from it what I need, and then present it in a brief form to consume and follow up if necessary.
So I put together the solution on AWS leveraging State Machines also known as Step Functions along with OpenAI API which will be reconsidered for alternatives in the future. I’ve coupled it up with Notion which is my favorite note-taking app but it also works well for storing and presenting information because of wondering API available.
I also used Apify SaaS for scraping content from publicly available cloud provider blogs with information extraction from various HTML tags.
And I want to present this solution to you so that you can also use this for your various needs adjusting it for your purpose.
System Architecture
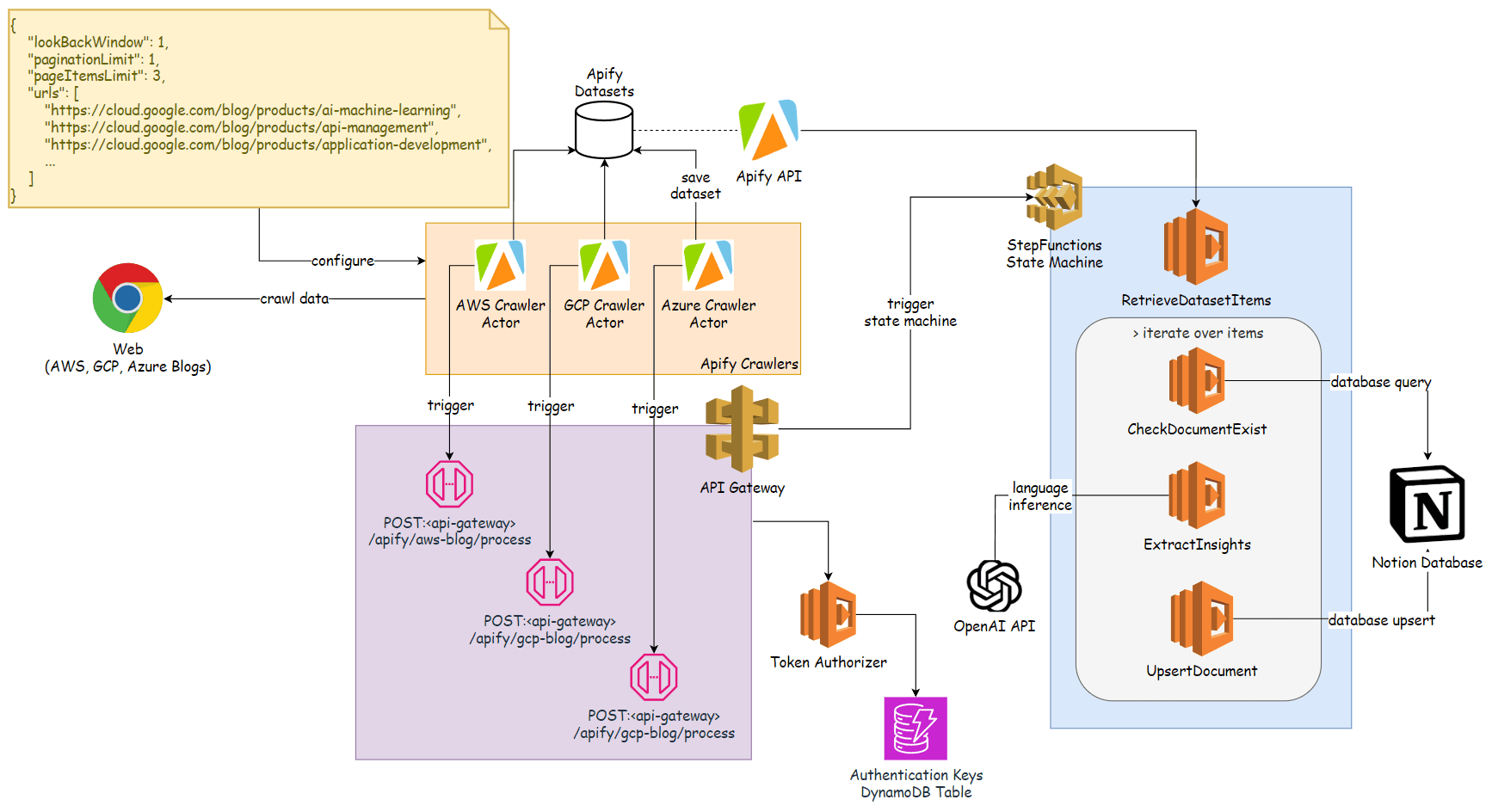
AWS Step Functions has been used as a automation engine cause it offers production ready capabilities in the cloud as well as various convenient features for controlling execution flow in an event-driven fashion, leveraging parallelization, logic flow, data mapping, error handling and retries, and granular observability. It also allows you to construct the logic in a visual builder accelerating development flow while offering a capability to export and define the logic in a declarative manner using IaC approach.
It also goes along with AWS Serverless Application Model that outlines a standard process in setting up your serverless application involving API Gateway to glue various services together and enforcing security and standardization. API Gateway also provides security features for endpint authentication and allows you to set up consumption plans to not overload the endpoints by the increasing number of incoming requests.
While scaping design in this particular solution revolves around Apify SaaS, AWS native offerings such as Lambda, ECS, EKS could also be considered for this purpose for further standardization withing AWS ecosystem cause that would offer much more significant benefits in terms of better security, higher cost savings, design robustness, etc especially when going down the road of an enterprise ready solution.
OpenAI is arguably the most powerful LLM engine offering fast and reliable API and matured client libraries making it a smart choice for initial design. They’ve also been the first ones who’ve implemented function calling through their API which is important feature for the tasks like when you need to extract particular information form the corpus of texts in a stable manner. To put simply, function calling guarantees an output format received form LLM which is important thing to reduce the number of retries on errors when parsing the output by the backend.
Finally, Notion is just a good interface if you don’t want to build your own frontend offering databases on the pages to structure and filter through information in a table form. Notion also has a great API to ingest and extract data from the service without severe limitations.
Apify for Crawling Web Pages
For low usage when scraping content, Apify could be just fine offering a low tier creator plan with with free credits provided.
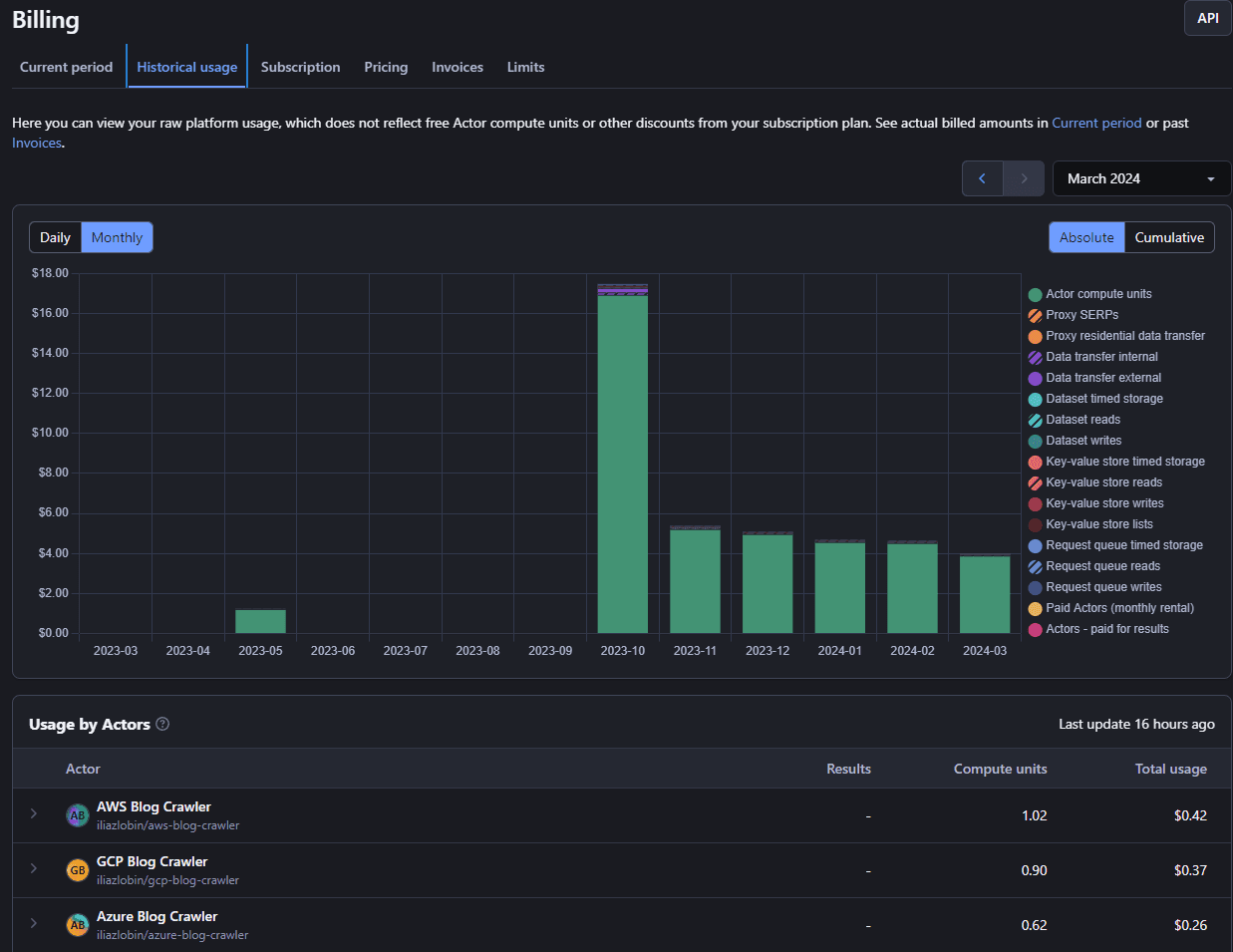
The good news about Apify is that you can always ports your crawlers to cloud compute environment rather easily cause they’re build on top of open source scraping (puppeteer, cheerio, crawlee, etc) libraries with Apify offering a set of wrapper libraries to execute anywhere you want.
Apify also lets you schedule actors to target desired blogs and configure particular configuration options around the crawlers (e.g. how many times to page through the blog, or how much deep into the history to look for relevant articles, etc) for a more autonomous behavior.
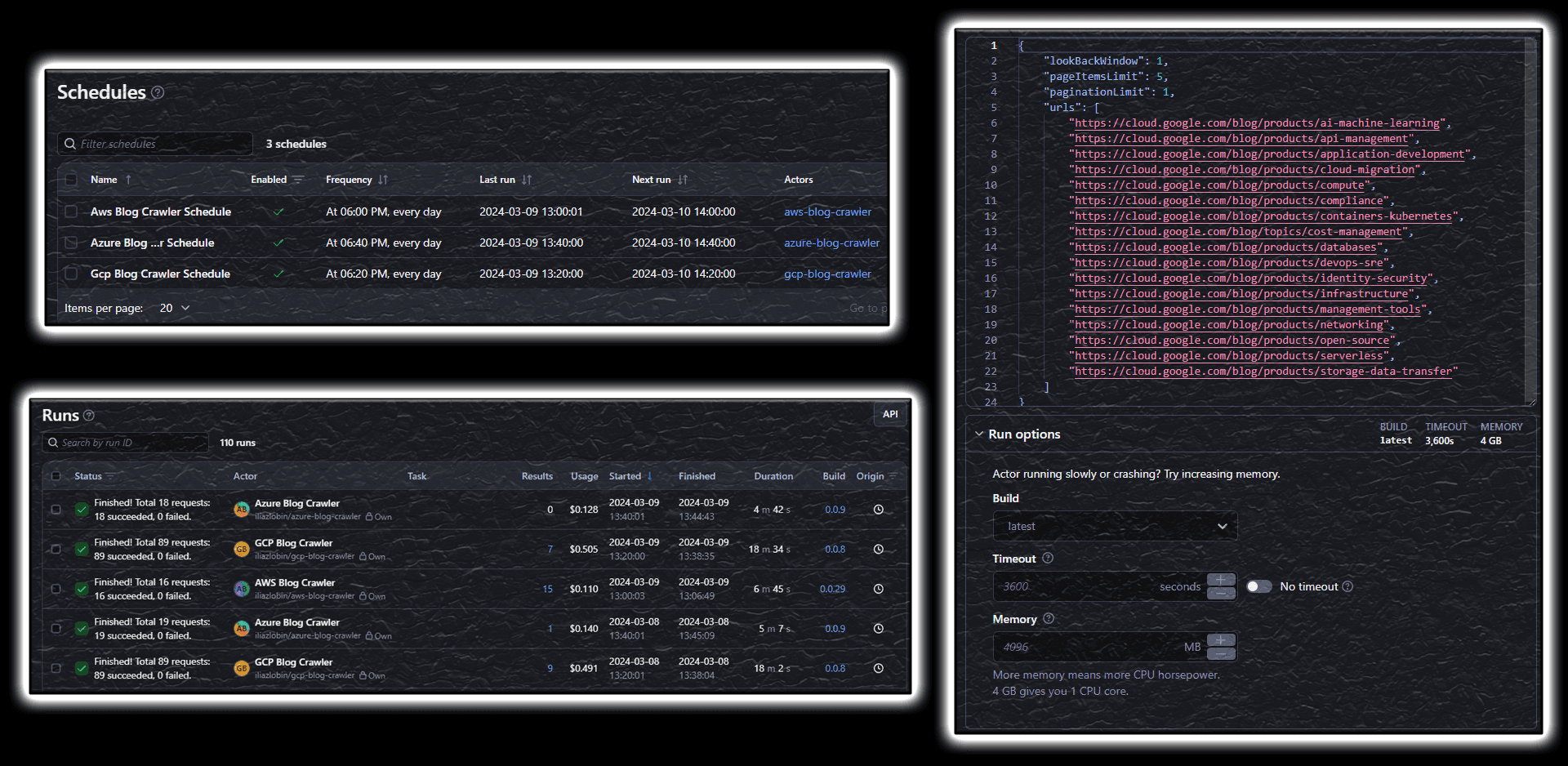
Apify is indeed not the only available service out there for crawling web pages, but it’s indeed the tool that met all my expectations and is not quite complex to learn and understand.
Alternately, you could also use LLM for data extraction from complete web pages without needing to know exact HTML tags or XPath to a required piece of data, and it’s even seemingly going to improve stability against slight tag changes on the pages, but you would definitely get more false positives where pieces of data aren’t retrieved at times, requiring you to put more evaluation guardrails around resulting in more compute consumption and perhaps more development effort in the first place.
Serverless Framework
In order to control your infrastructure in a more reliable manner and to unlock a possibility to expand to more environments with more people involved and even offering multi-tenant solutions through a marketplace of such, you want to properly approach deployment procedure. That typically involves defining your deployment configuration in code using declarative specification for which you can use very many tools such as Terraform, CloudFormation.
But my choice has fallen onto Serverless Framework that’s specifically attuned for serverless solutions. With it, the deployment is simplified to just defining one yaml specification with the most important pieces that outline deployment and it does the rest of work for you managing a few heuristics you never have to think about such as managing IAM and API Gateway. It’s also flexible enough to still be able to define certain options for tweaking security, defining your own CloudFormation resources, if you ever have to.
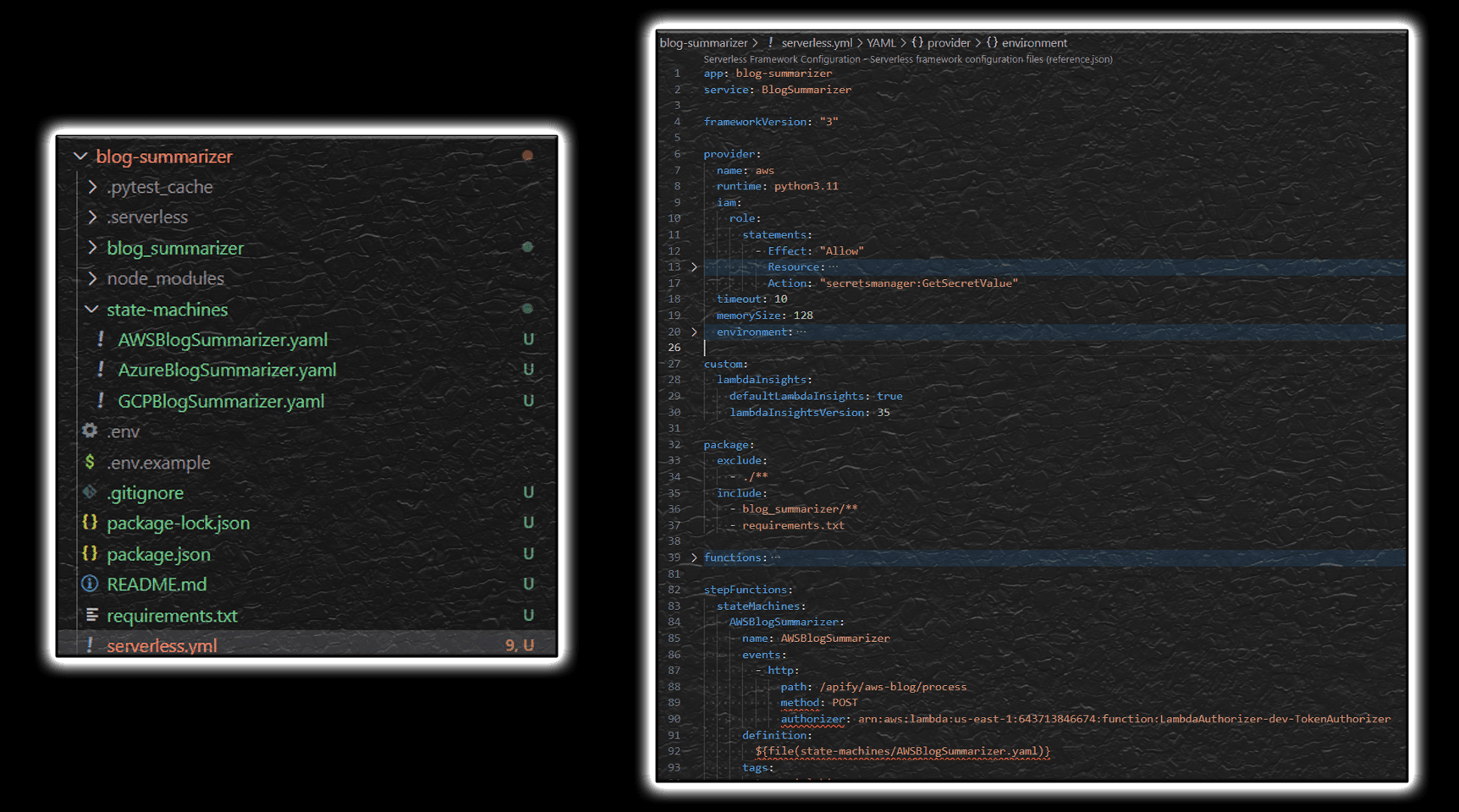
Serverless framework supports python and nodejs runtimes with local debugging capabilities to accelerate development flow and has a bunch of plugins available for additional AWS features enhancing production readiness such as Lambda Insights, Step Functions support, zero-config, etc.
Why Step Functions?
Step Functions is an excellent framework to connect serverless compute execution elements in an event driven fashion. It supports defining parallel execution, loop-iteration through map-reduce data pattern (including distributed processing), basic choice logic, data transformation, and more. It also integrates with virtually any AWS service through API call mapping right in the calling specification freeing you from an extra lambda call, this makes it very versatile how you can use it within AWS ecosystem. And if you want to integrate it with external APIs, you can always use Lambda, the very first choice when working with Step Functions.
But what makes it truly beautiful is an ability to leverage a visual builder when putting together the flow. It also nicely lands onto your IaC specification by offering code specification for whatever you’ve configured in the builder straight away.
Data mapping is something you’ll have to keep in mind when connecting various elements. But luckily, AWS also has your back by offering Data Flow Simulator allowing you to experiment with data mapping prior to executing your flow.
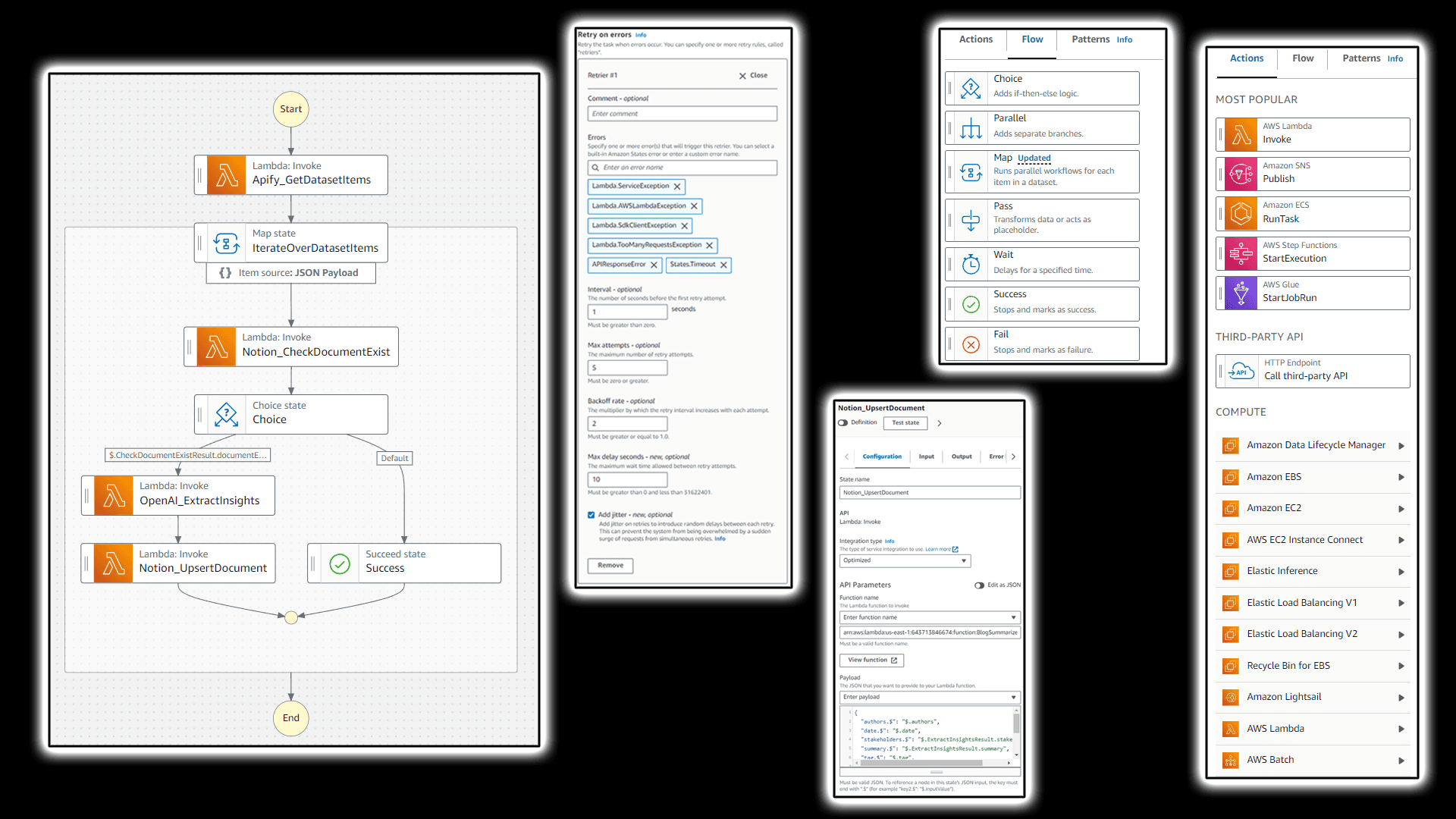
OpenAI Integration
OpenAI plays a significant role in this solution by providing LLM capabilities for text summarization. In principle, any LLM could be use for this purpose including the ones available with AWS Bedrock. But given that OpenAI provides the most advanced GPT models and very capable API with function calling, that’s what has been chosen for this solution for the first iteration. Later, Bedrock models as well as open LLM models could also be considered for simple tasks such as summarization enhanced by fine tunning and instruction following training as it’s becoming more and more available.

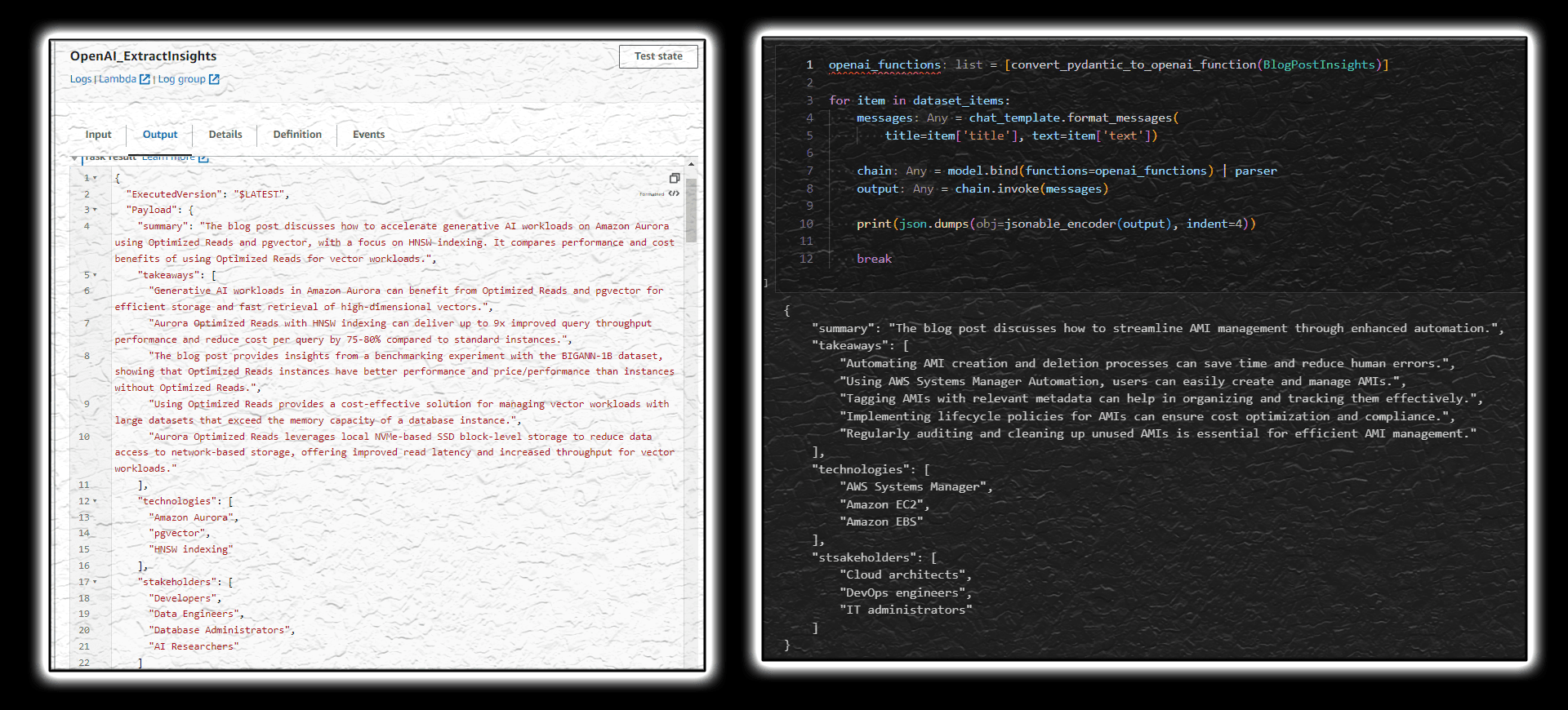
Langchain framework has matured enough to make code integration nice and smooth. Function calling becomes as straightforward as defining a Pydantic class in Python with a parser extracting information from the OpenAI response into the corresponding structure.
class BlogPostInsights(BaseModel):
"""Blog post insights."""
summary: str = Field(description="one sentence sumamry of the blog post")
takeaways: List[str] = Field(
description="3-5 (depending on the length of the blog post) key takeaways from the blog post"
)
technologies: List[str] = Field(
description="the key cloud services and technologies mentioined in the blog post"
)
stakeholders: List[str] = Field(
description="groups of stakeholders who would be interested in the blog post"
)
def get_blog_post_insights(title, text, cloud):
chat_template = ChatPromptTemplate.from_messages(
[
SystemMessage(
content=(
"You are a professional cloud architect with solid analytic skills. "
"You know everything about {cloud} and are always up to date with the latest news. "
"You excel at analyzing blog post articles taking clear summaries and takeaways. "
)
),
HumanMessagePromptTemplate.from_template(
"I want you to analize this blog post and provide me with the key insights about it. "
"Blog post title: {title}. "
"Blog post text: {text}. "
),
]
)
//...
openai_functions = [convert_pydantic_to_openai_function(BlogPostInsights)]
parser = PydanticOutputFunctionsParser(pydantic_schema=BlogPostInsights)
chain = model.bind(functions=openai_functions) | parser
output = chain.invoke(messages) // BlogPostInsights object
Deployment Flow
Once you’ve developed and tested your Apify crawlers, and confirmed your packages work locally, you’re going to want to proceed with deployment and testing in the cloud. That would also take a couple iterations of deploying code through serverless cli and testing execution by sending an expected Apify payload to the endpoint.
AWS Step Functions offers incredible execution visualization while sourcing information from corresponding services (CloudWatch, Lambda, etc) to give you enough details to understand what went wrong and how to fix it. You can also as deep as you want to simulate and test things individually to fix in isolation which is always a good idea before repeating a step machine exercise.
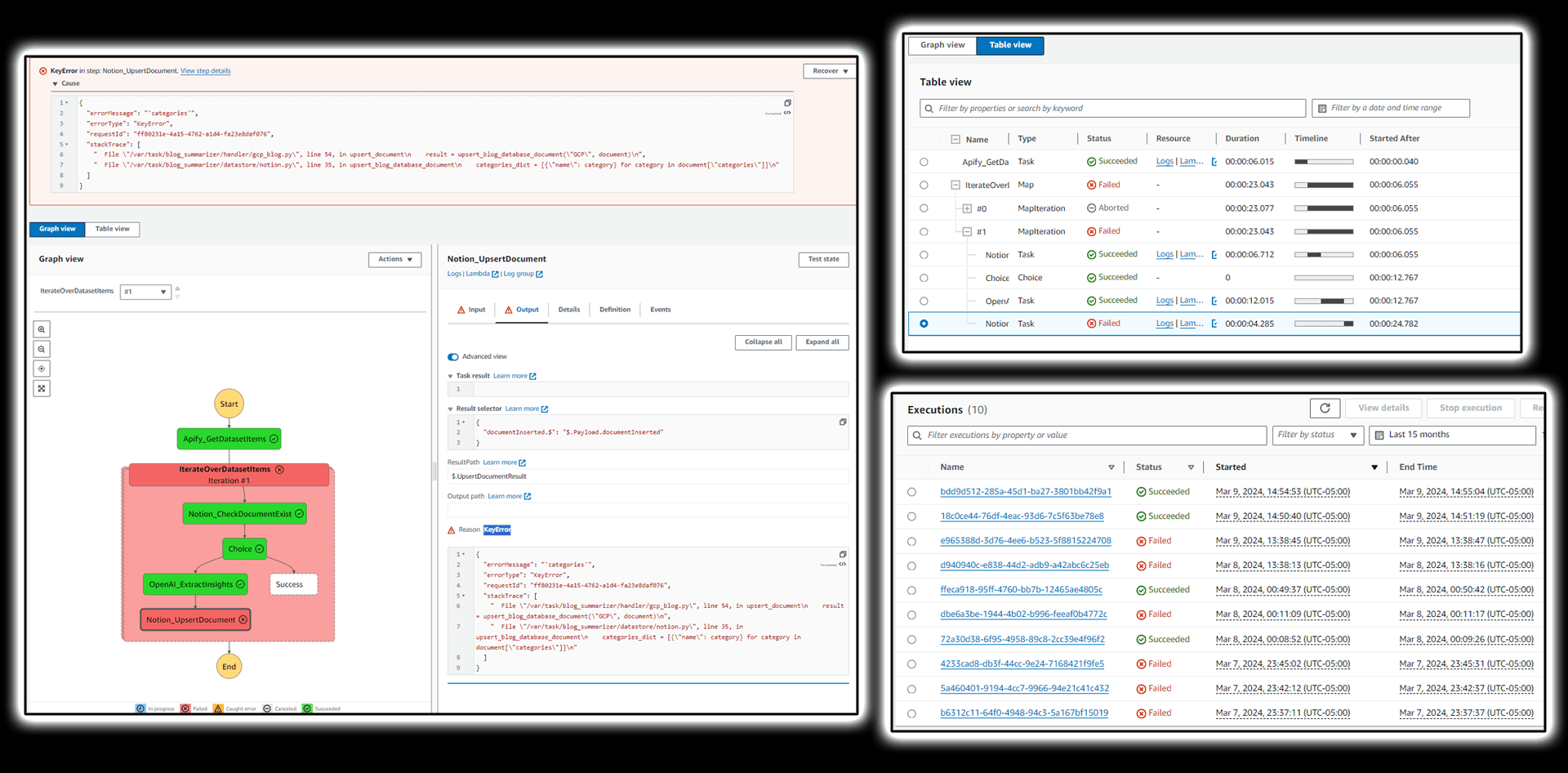
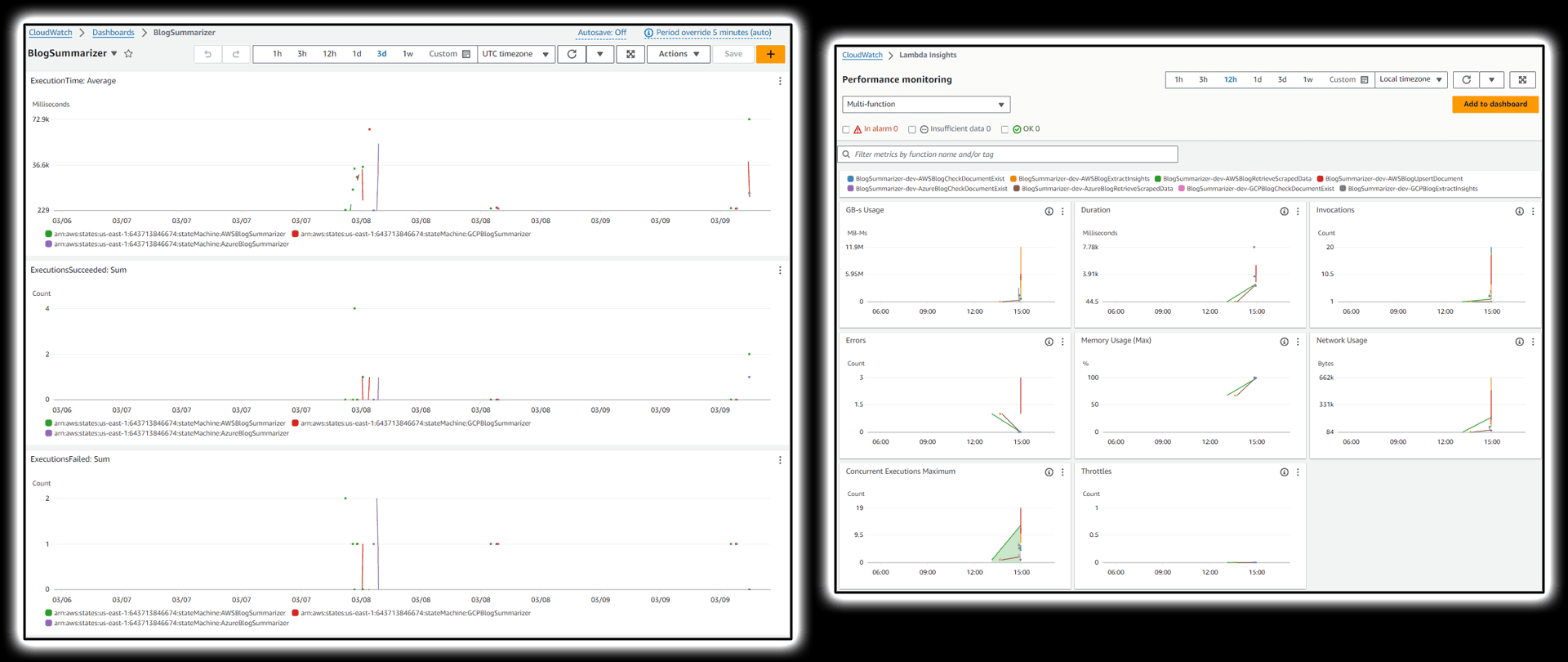
The service leaves a good trail of executions in form of various metrics and logs you would also want to use to understand how things are at on a higher level once you’ve been running a thing for some time.
Authentication
In order to protect your endpoints to where Apify is to ingest payload data, you can want to set up authentication in API Gateway. It supports multiple schemes through IAM and Cognito, but for this specific case not involving external users where Cognito would be an excellent choice, a simple lambda authorizer checking a generated bearer token seems to be a viable option.
Lambda authorizer is out of the scope of this article, but to put simply, it’s just another lambda function that checks that the bearer token sent along with a HTTP request matches the one stored in a Dynamodb Table providing enough permission for the principle to trigger a certain Step Function.
Infrastructure as Code and Configuration
Currently, all code is located in corresponding repositories with README instructions on how to deploy it from your local environment. You can potentially further improve the deployment experience by putting together GitHub Action Workflows that’d automatically deploy code to your cloud environment on PR merges.
- https://github.com/iliazlobin/blog-summarizer
- https://github.com/iliazlobin/apify-aws-blog-crawler/
- https://github.com/iliazlobin/apify-gcp-blog-crawler/
- https://github.com/iliazlobin/apify-azure-blog-crawler/
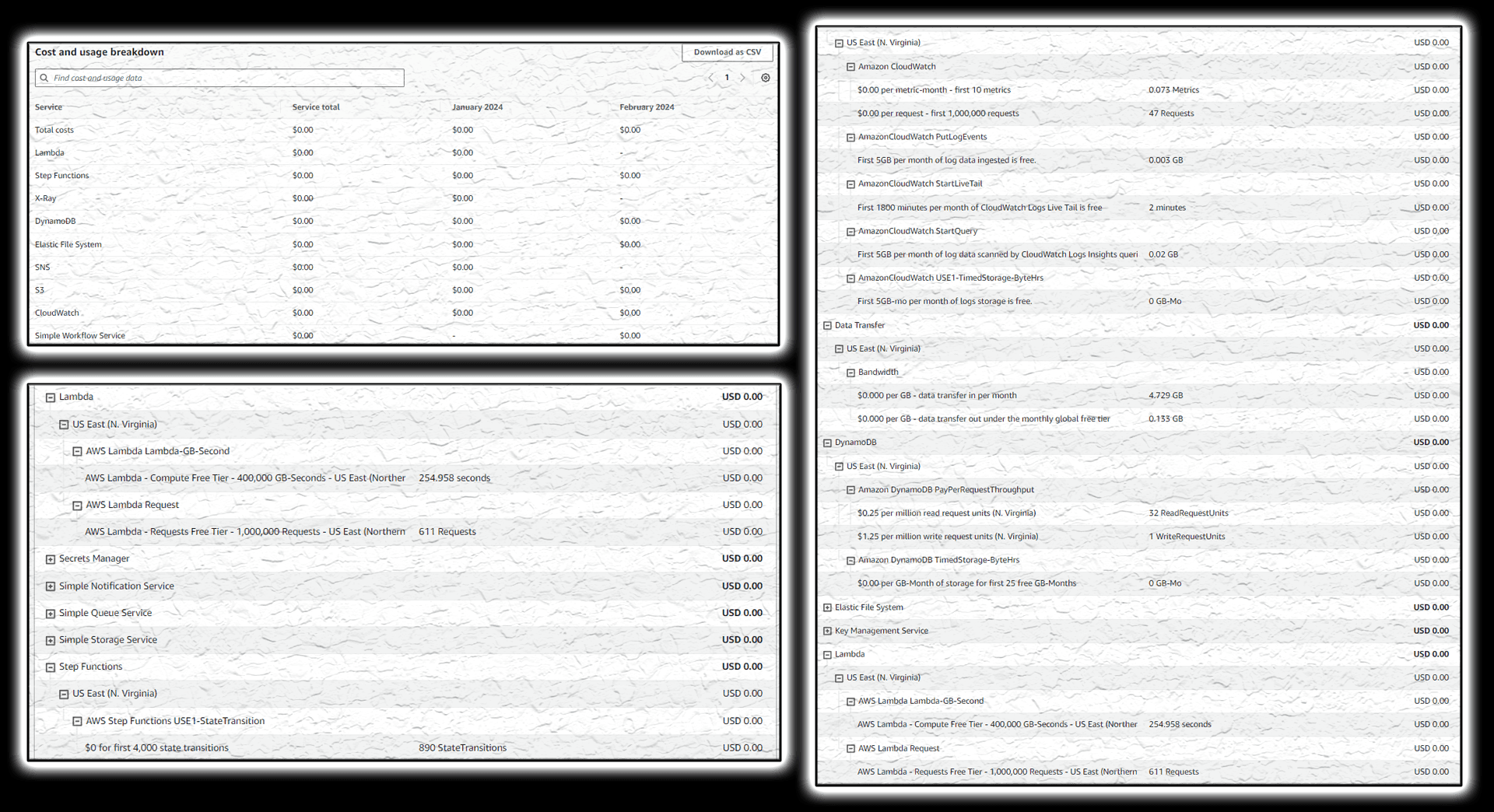
Costs and Usage
Once everything is in place, you’re getting a reliable production ready system that given you’re on a Free Tier, isn’t going to cost you anything brining you confidence that you can experiment with the system without breaking a buck.
But even if you’re beyond free tier, given that the system leverages the concept of even-driven design, you’re going to be charged only for what you use releasing you from undesired spend like long-running underutilized instances which translates for this particular solution in a very low amount.
Still, with usage increase, you can always optimize the approach by offloading some long-running operations to other cost-efficient compute services such as ECS, EKS and even leverage other cost savings strategies like savings plans and spot instances.
Final Look
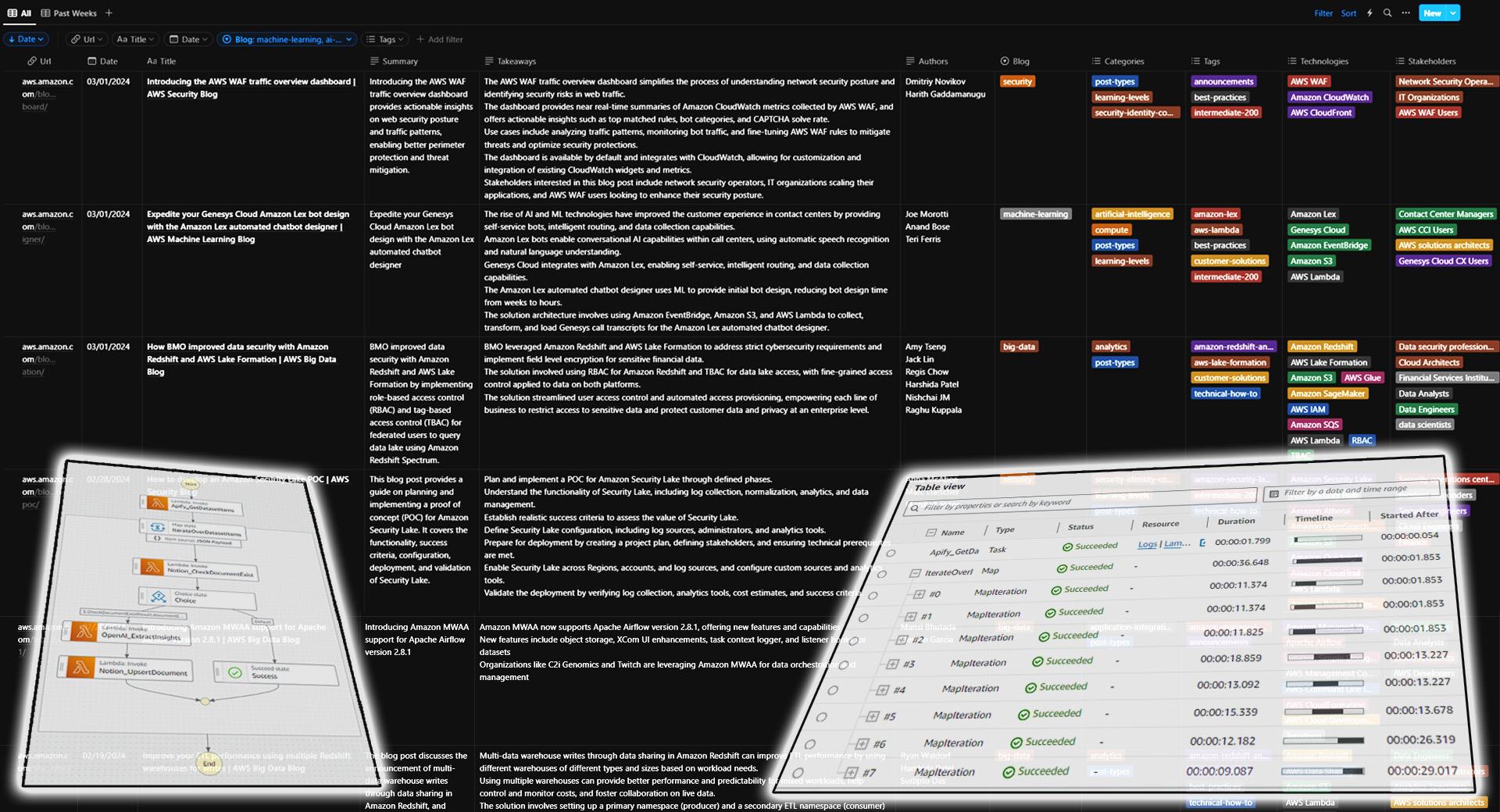
Once everything is in place, Notion will keep accumulating blog post articles in a database daily by structuring it in a table with corresponding blog summaries and metadata allowing you to navigate through the content.
You can further customize the solution by extracting more data through corresponding prompt modification and adjusting function calling parameters. You can also include more blogs by writing another crawler in a similar manner.
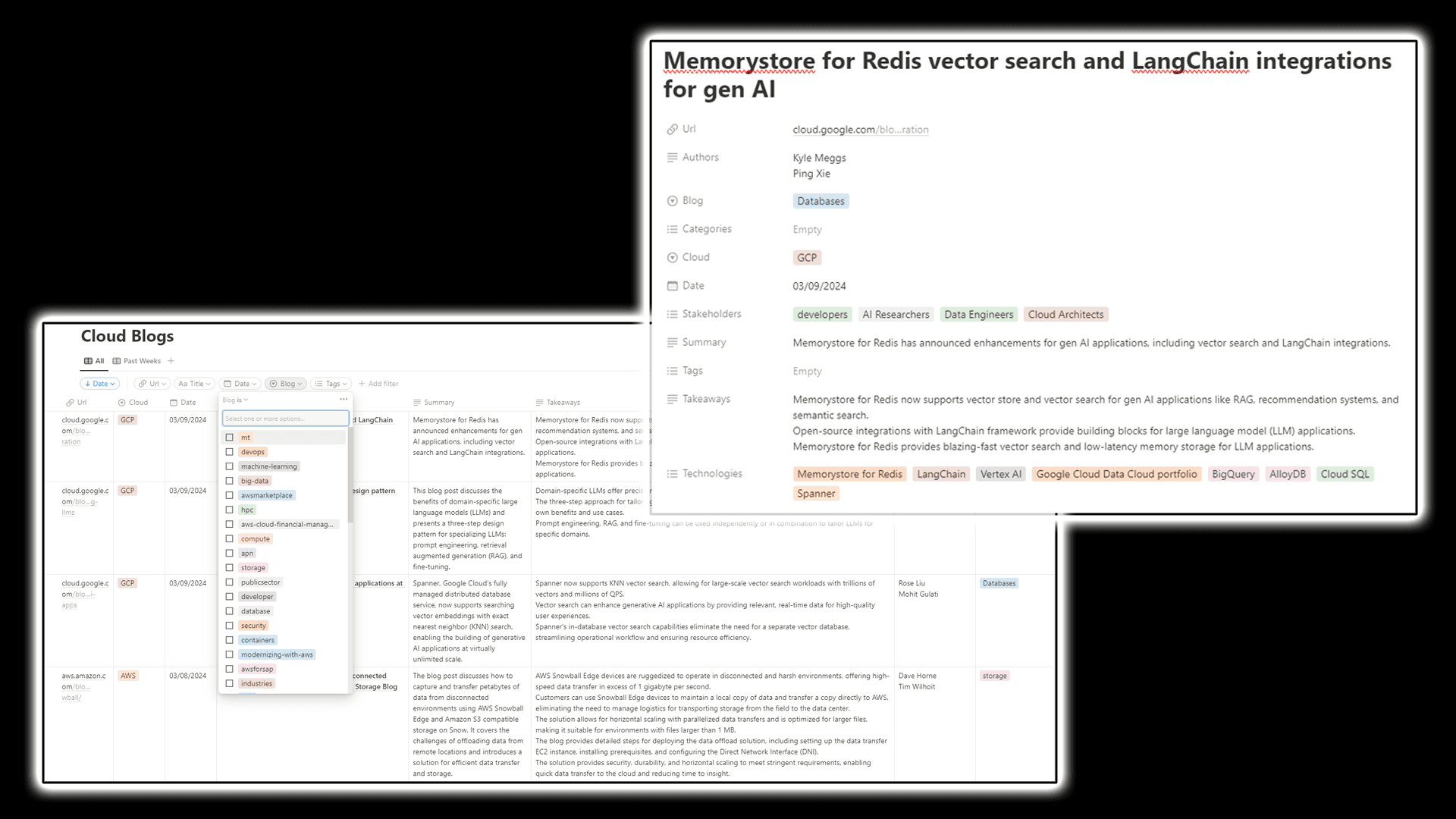
I’ve also made the final database notion page publicly available that’s going to be dynamically updated every day so that you can use as a product for your particular needs or just give it a try and see if this is something you’d like to build similarly with the content of your interest.